The primary target audience for a Brain-Computer Interface for Imagined Speech Classification are those with temporary or permanent speech impairments, such as individuals recovering from stroke or traumatic brain injury, as well as those with degenerative neurological conditions like Amyotrophic Lateral Sclerosis (ALS) or locked-in syndrome.

In an attempt to provide a means of communication for individuals who have an impaired ability to speak, I propose Verbalize: an Imagined Speech Classification Model that predicts what the user is trying to say by analyzing their EEG signals.
Brain–computer interfaces (BCIs) have the potential to significantly improve communication for individuals who are unable to use traditional augmentative and alternative communication (AAC) devices due to insufficient residual muscle activity. Additionally, BCIs can provide more natural and intuitive control over assistive devices compared to traditional AACs, making them a promising alternative for enhancing the independence and quality of life for those with severe communication impairments.
Currently, there are Augmentative and Alternative Communication (AAC) devices available to help people "speak". There are no-tech, low-tech, and high-tech options available, the most popular being text-to-speech applications that can be installed on handheld devices such as a mobile phone or a tablet. This is how Verbalize compares to them.

The major advantage of existing AAC devices is that imagined speech recognition is very hard to implement and they are more easily accessible. Additionally, creating a generalized solution for imagined speech recognition is challenging due to anatomical differences between individuals.
Despite these limitations, exploring Imagined Speech Classification is still compelling. With ongoing advancements in technology and extensive research conducted in this field, this approach has the potential to evolve into a viable solution in the future.
This means a considerable amount of people can benefit from such a product being developed. Based on the information collected thus far, I was able to create a User Persona for a potential user of this product.

The dataset that I will be using to train an Imagined Speech model is from the 2020 International BCI Competition. This dataset contains 5 labels which are Hello, Help me, Stop, Thank you and Yes which are commonly used phrases.
The dataset includes recordings from 15 individuals. To balance training time and enhance the model's generalization capabilities, I will use recordings from 5 of these individuals.
After analyzing and understanding the dataset, I converted the MATLAB File to a CSV File that I can use to create a Model. I then realized something...
The dataset comes with the recordings for all 64 Channels. We can't expect our users to wear a 64-Channel EEG Cap during all times so we need to choose a more realistic option.
The alternative option was to look at existing portable EEG headsets and focus only on the channels they can record. However, by reducing the number of channels used, we are decreasing the amount of information being recorded, which can result in reduced accuracy. This is a trade-off I have to consider. Two options of portable EEG Devices I considered were:

I will be thoroughly experimenting with both the 8 Channel Dataset and 14 Channel Dataset and will be choosing the one that results in a higher accuracy.
After a lot of experimentation, the 14-Channel Dataset was performing considerably better than the 8-Channel one. This was the model I settled with and it achieved an accuracy of 61% on a test set consisting of 250 Trials after being trained on 1500 Trials. My reason for choosing an LSTM (Long Short-Term Memory) lies in its ability to selectively remember or forget information from the previous time steps. This makes it suitable for processing time series data such as EEG signals, where the order in which signals appear is very important.

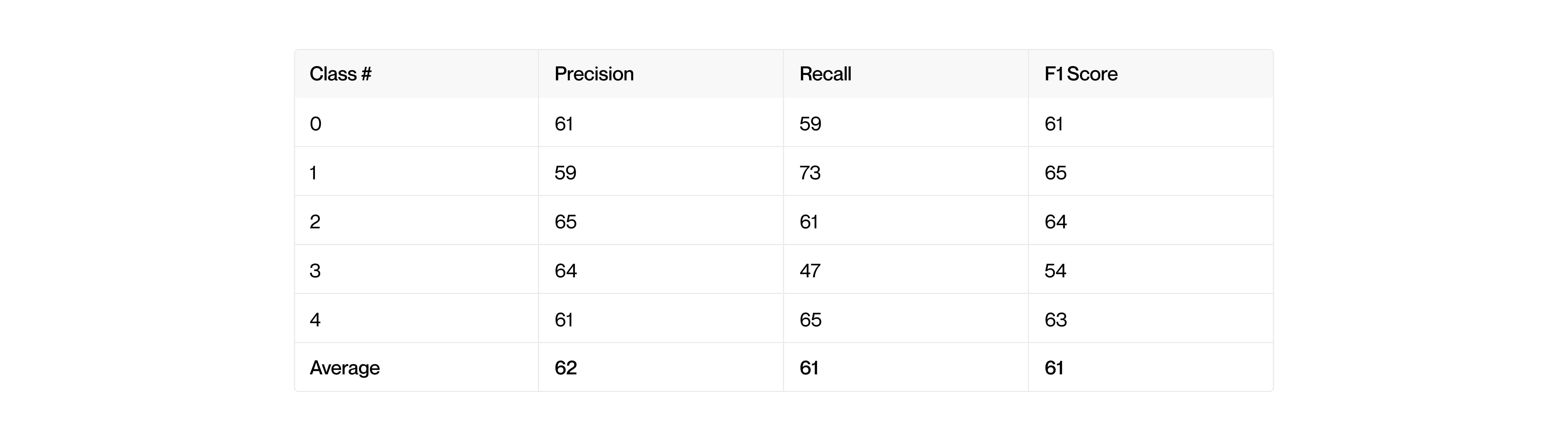
To examine the class-wise performance, I calculated the F1, Precision and Recall scores of the model for each class. From this, we can see that the model performs best at classifying Class 1 while the model performs worst at classifying Class 3. Perhaps the data for Class 3 is too similar to the other classes, leading to wrong classification. It's also possible that the Class 3 data has fewer distinct patterns or features that the model can learn from, making it harder to classify accurately.
As I have mentioned before, this is only the starting point to demonstrate a working prototype as the dataset only contains 5 labels. As the number of labels increases, the complexity of the model will also increase. It may require more advanced methods such as transfer learning or using ensemble models to create a fully working imagined speech model that can replicate regular speech. Building such a model will require a lot of expertise, experience and research. It can also be expensive to acquire and process the data required to build the model. Regardless, I am confident that my initial prototype can serve as a good starting point to find a working solution.
The best model is tailored for each individual, but it is not a practical approach to bring in a specific user to collect their data and design a model solely for them. One method to circumvent this is by increasing the number of participants from whom the EEG data is collected and thus, somewhat generalizing the model, but this process can be very expensive and time-consuming. It is better if the participants of the data collection are part of the intended audience for the EEG headset. This is because the EEG signals can vary significantly across different populations, and therefore using data collected from individuals who are not representative of the target audience can lead to a less accurate model. In addition, if the participants are part of the intended audience, they may be more motivated to participate in the data collection process as they may be eventual users of the product.
In case you want to contact me for further projects, you can reach out to me at pradhyumnaag30@gmail.com.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6698623/
https://www.who.int/news-room/fact-sheets/detail/spinal-cord-injury
https://www.emotiv.com/product/emotiv-epoc-x-14-channel-mobile-brainwear/#tab-description
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5968329/
https://www.sciencedirect.com/science/article/abs/pii/B978044463934900007X