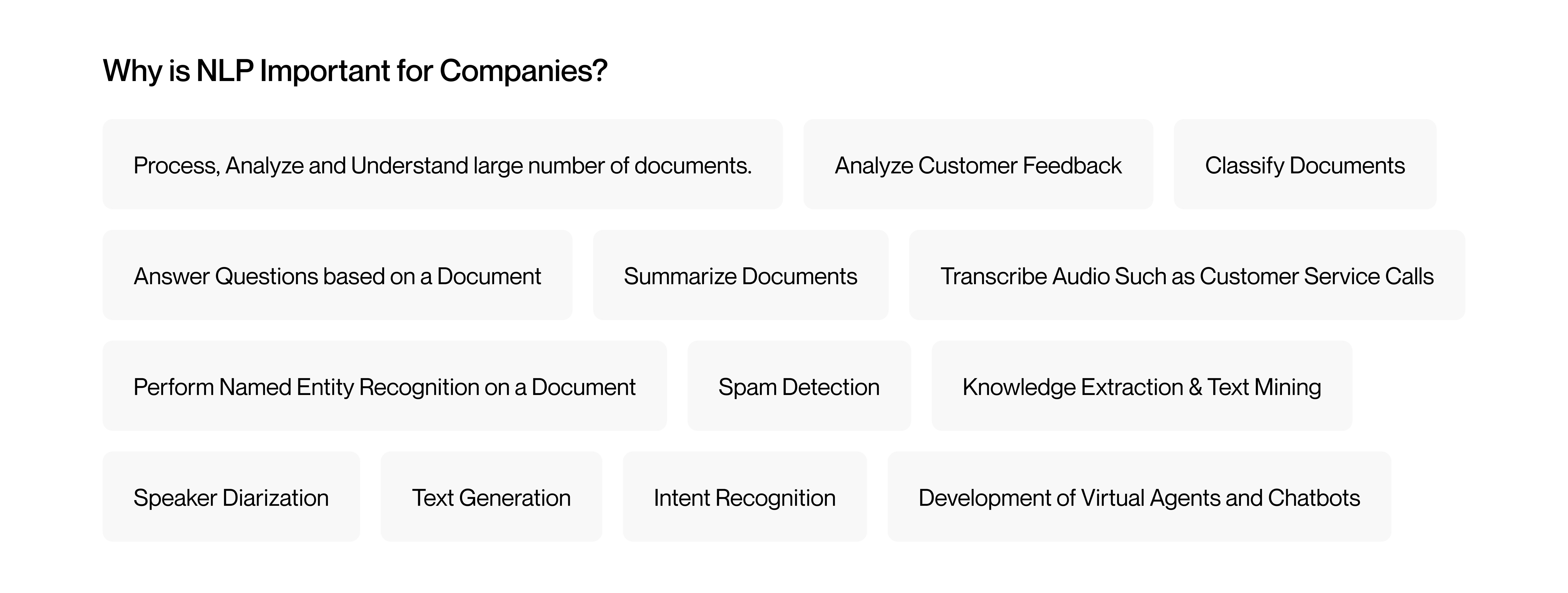
Many companies deal with huge volumes of text and speech data. NLP helps them analyze and understand this information efficiently, automating tasks like classification, summarization, and transcription — exactly what Spectrum is designed to handle.
As text and audio data grow, companies struggle to process and understand it all by hand. Manual work is time-consuming (Parseur reports employees spend 9+ hours per week on manual data transfer), expensive (Ardent Partners 2024 found invoice errors and manual handling can cost companies $10–$30 per invoice), limited in scalability (IBM estimates 80–90% of enterprise data is unstructured and difficult to process manually), and prone to errors (Invensis notes manual data entry error rates range from 0.5%–4%). These challenges make automation with NLP essential.

Users face several challenges with NLP tasks, from accuracy and scalability to integration with existing systems. Drawing on insights from platforms like Amazon Comprehend, Google Cloud Natural Language, Azure Cognitive Services, and IBM Watson, I mapped out what users expect and how Spectrum could meet these needs.
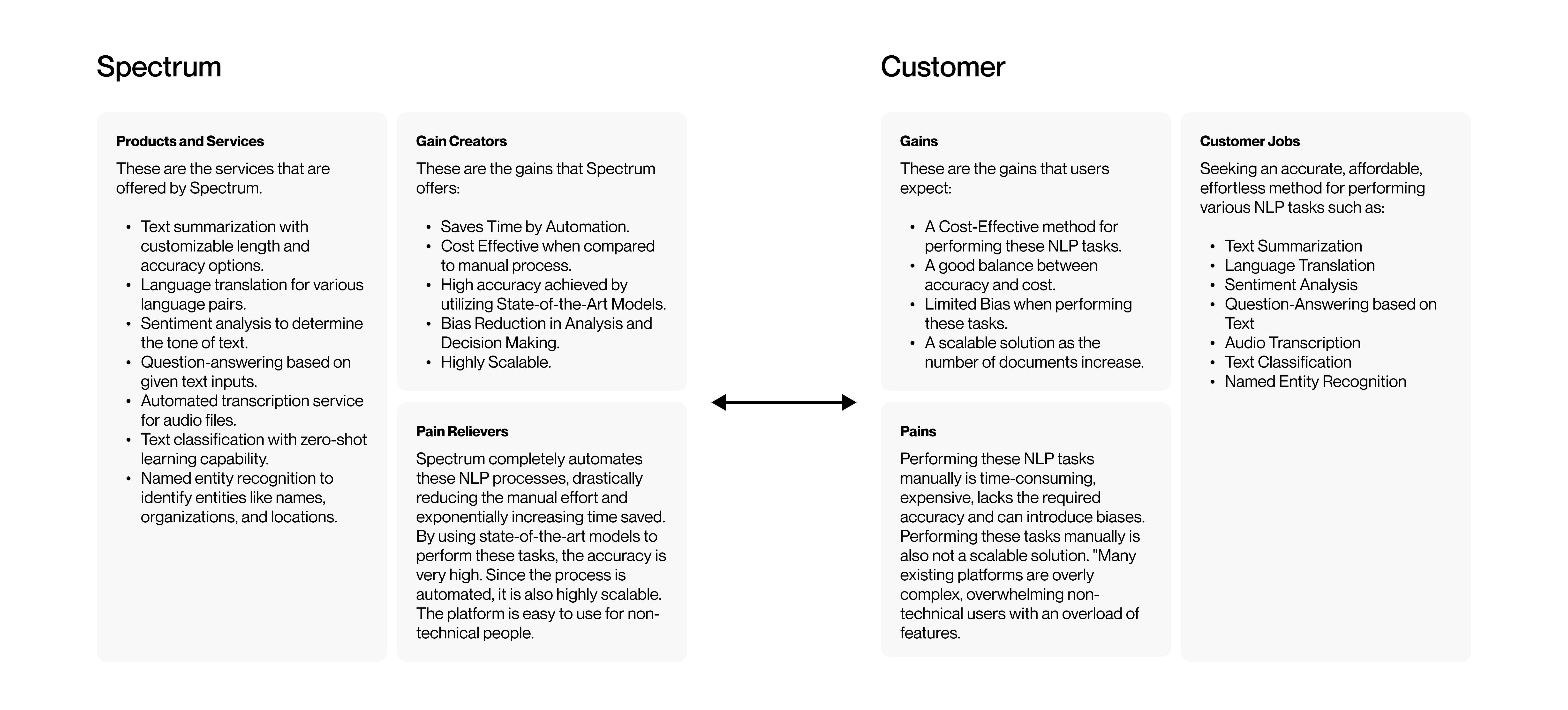
While Spectrum may have slightly lower accuracy for some tasks compared to platforms using custom-trained models, it offers a much simpler experience, making it easy for non-technical users to learn and use — which is Spectrum's core advantage.

When creating a new product, it is essential to focus on the minimum set of features needed to meet core user needs. This allows you to launch quickly with a Minimum Viable Product (MVP), validate the concept, and start learning from real users.
Releasing an MVP early lets you gather feedback, test assumptions, and improve the product based on real user needs — shaping it into something truly useful.

While many MVPs start with just one core feature, the competitive landscape — with platforms like Amazon Comprehend, Google Cloud, and Microsoft Azure — means a single tool isn't enough to stand out.
That is why Spectrum offers a full suite of NLP capabilities from the start. By combining multiple powerful services in one platform, it helps users work more efficiently, gain deeper insights, and handle all their NLP needs in a single, streamlined solution.

Instead of training custom models on limited data, I chose existing state-of-the-art models for Spectrum. This delivers strong results right away, saves time, and keeps costs low — perfect for an MVP. The tradeoff is less control over domain-specific nuances and fewer options for customization. As Spectrum grows, these are exactly the kinds of advanced features on the roadmap.

Spectrum is built to make NLP simple, effective, and competitive, while keeping the experience hassle-free.

The flow stays largely the same across all functionalities, making it easier to learn and more familiar to use. Each feature has slight differences in customization and the data dashboard to suit its specific needs. Occasionally, outputs like translations or classifications might not be fully accurate. To ensure precision, users can review and edit results directly — keeping the experience flexible and user-friendly.

I explored each feature of Spectrum separately, building both the model implementation and a dedicated high-fidelity prototype for each, rather than combining everything into one large flow.
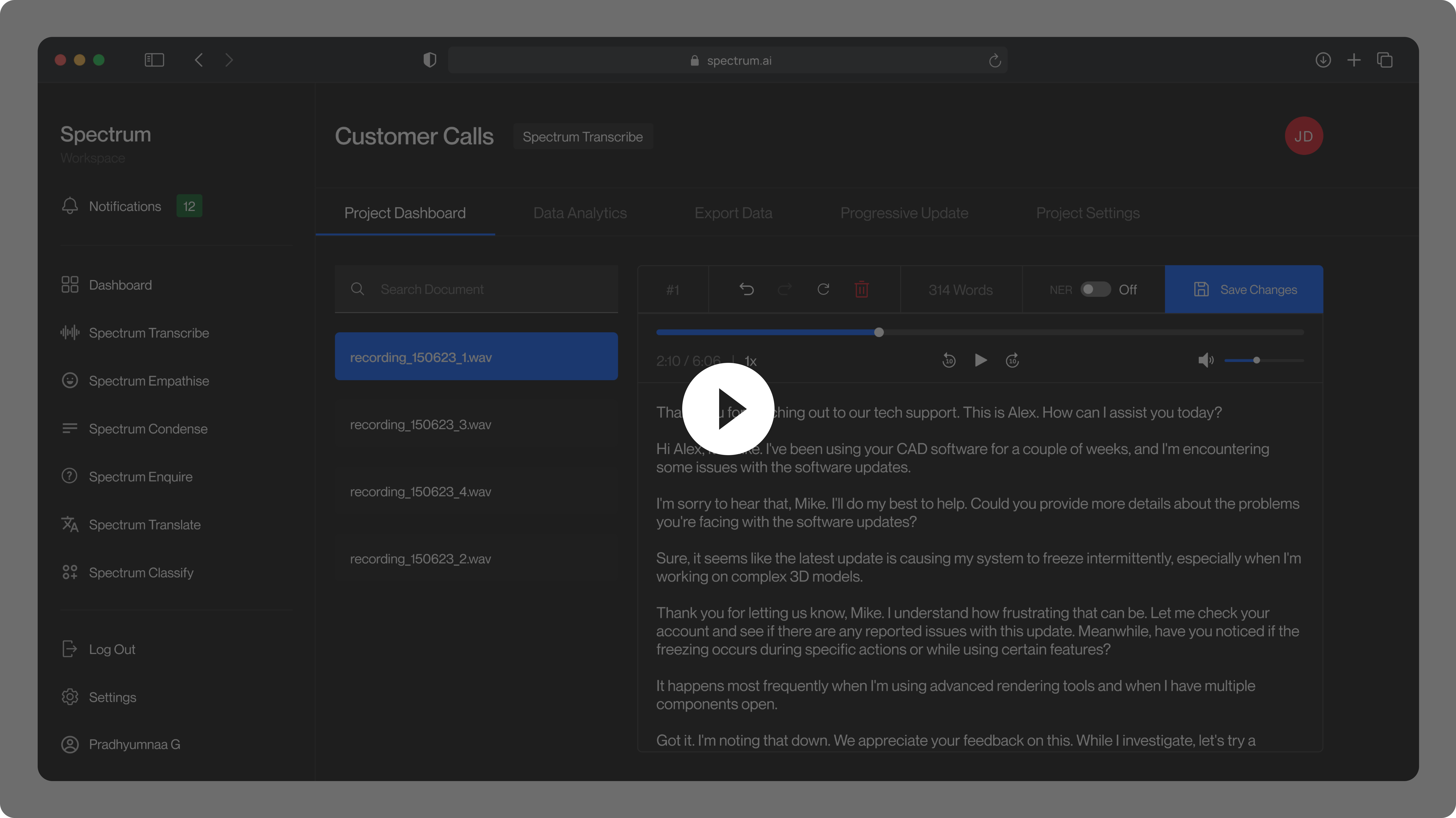
Given an audio file, Spectrum Transcribe uses Facebook's Wav2Vec2 model to accurately convert speech to text. While this version doesn't include speaker diarization, it can be extended later with libraries like Kaldi.

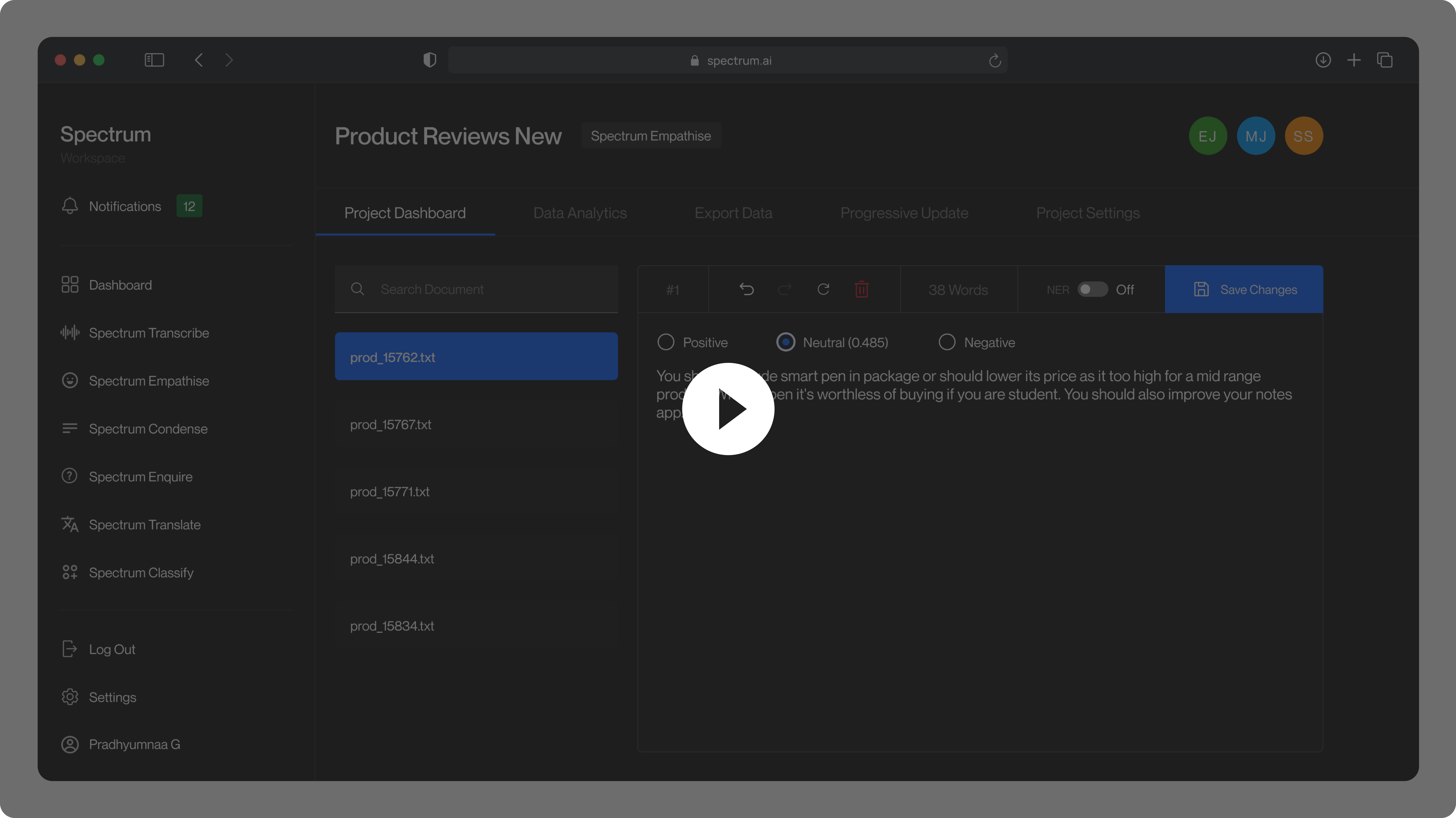
Given a text, Spectrum Empathise classifies its sentiment as positive, negative, or neutral, using Cardiff NLP's Twitter-RoBERTa model. Since the model was trained on 124M tweets, it works well for general text but may be less reliable for domain-specific use cases.

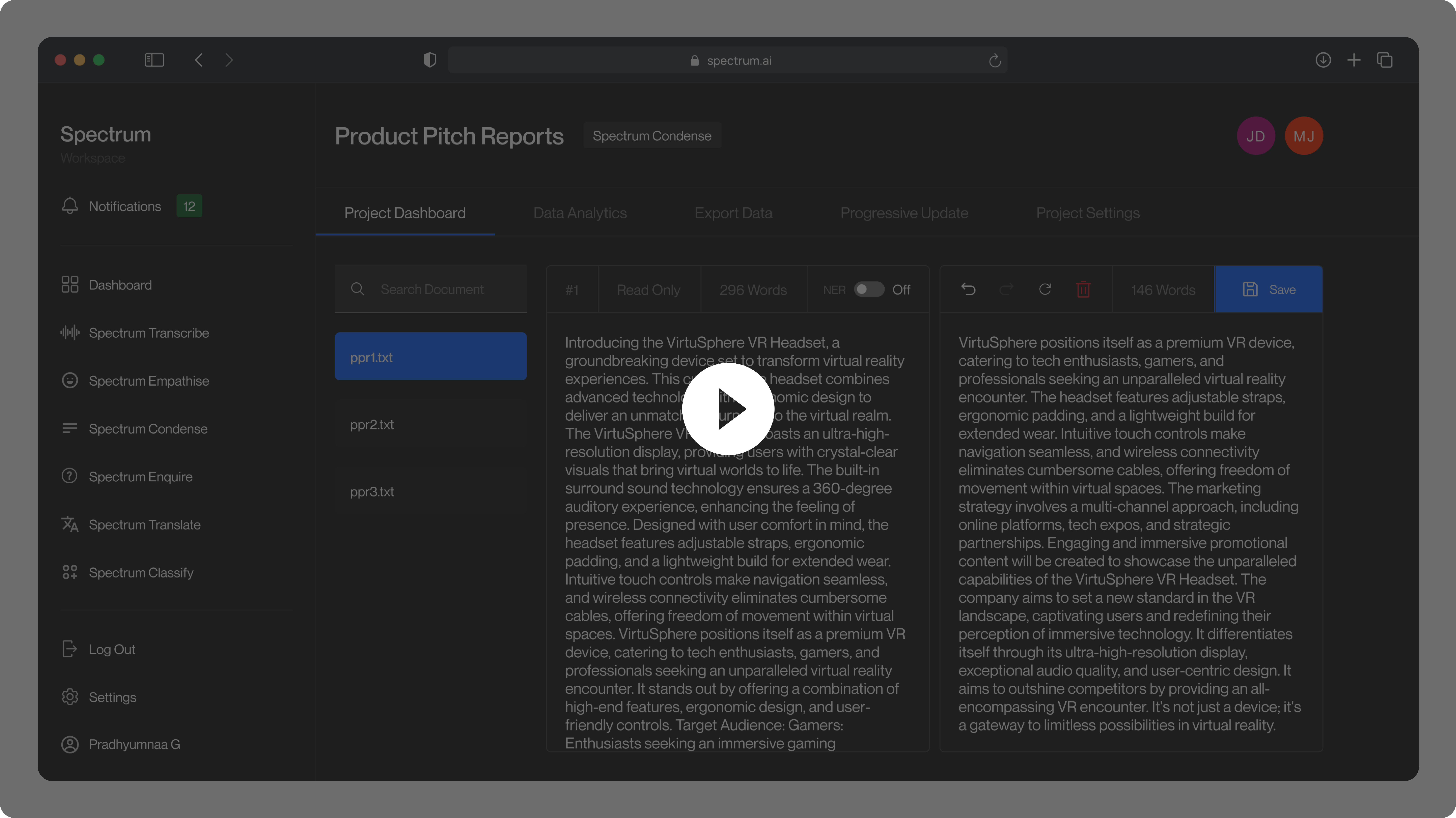
Given a text, Spectrum Condense creates a concise summary that preserves the key information. Users can also adjust the summary length within a chosen range. This feature is powered by Facebook's BART-Large-CNN model.

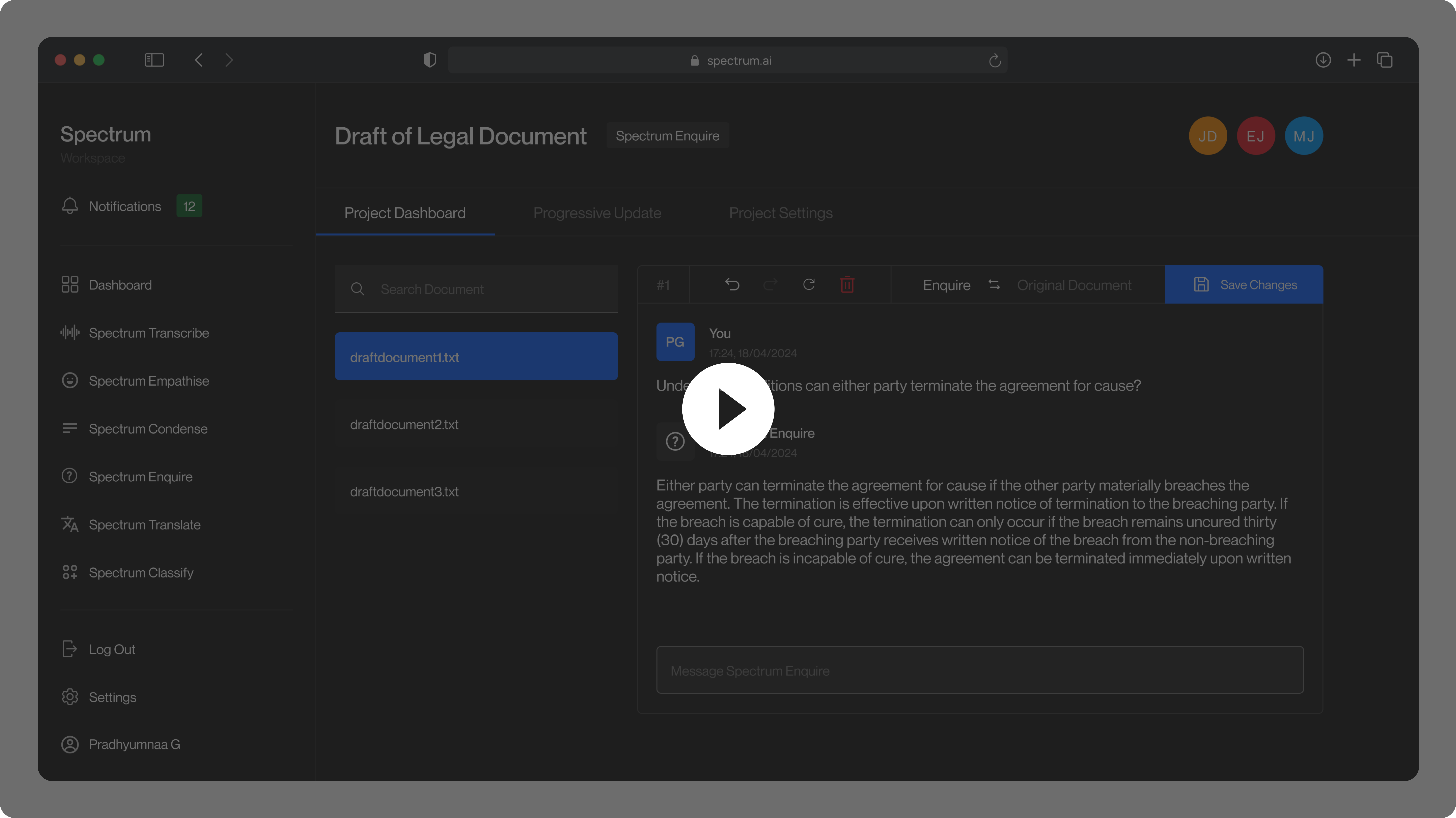
Given a text, Spectrum Enquire answers questions related to it, using Deepsets's Deberta-v3-Large-Squad2 Model.

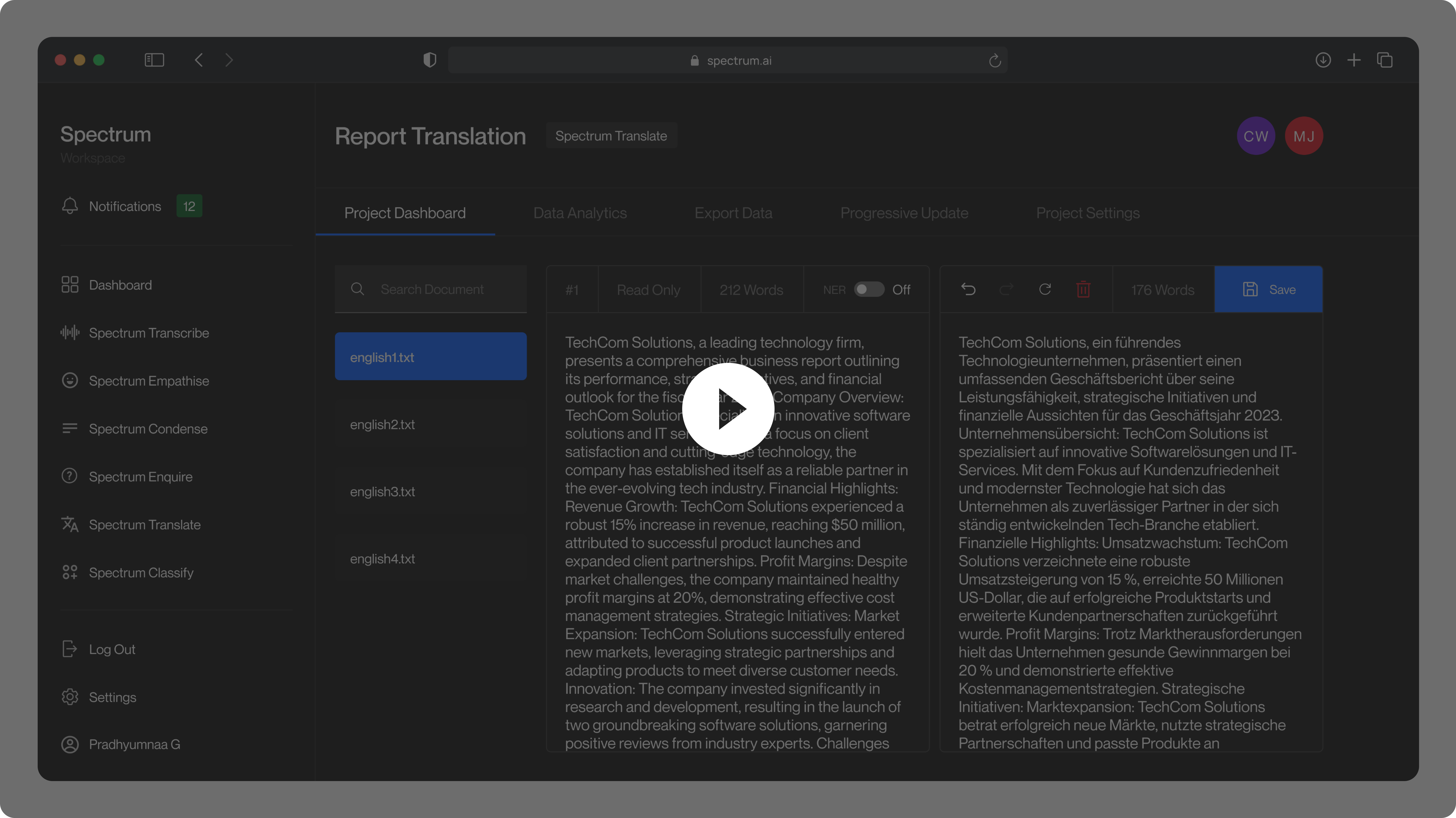
Given a text, Spectrum Translate converts it into the target language chosen by the user. The current implementation handles English to German using the University of Helsinki's Opus-Mt-En-De Model, but it can be expanded to support other language pairs.

Given a text, Spectrum Classify uses Facebook's BART-Large-MNLI model to assign it to categories defined by the user. As a zero-shot classifier, it can handle new, unseen classes — but needs the user to provide a list of possible labels for each task.

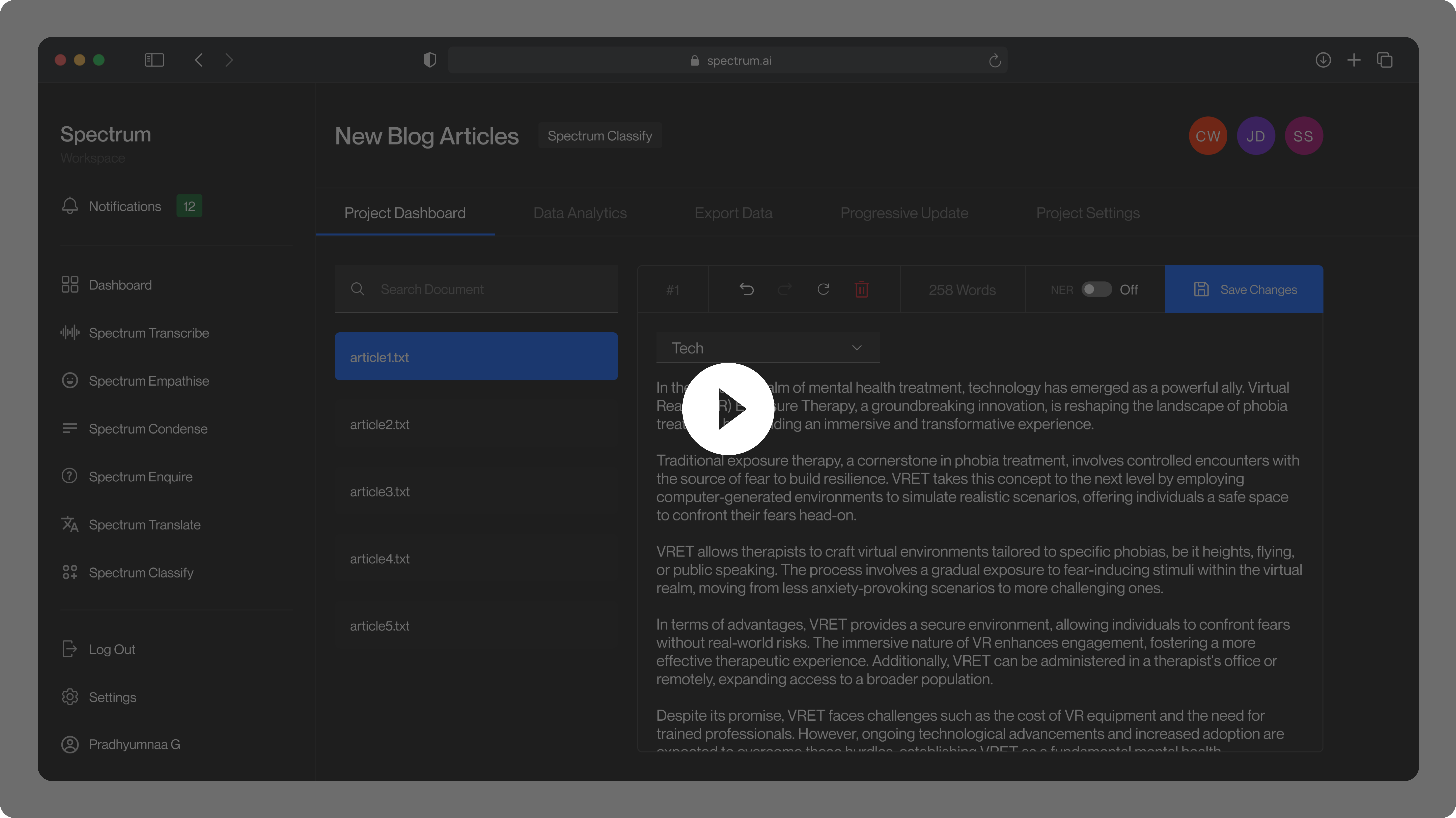
Given a text, Spectrum Recognize performs Named Entity Recognition (NER), identifying entities across 18 predefined categories. This is implemented using Flair's NER-English-Ontonotes-Large model.

Spectrum is a user-focused tool that makes complex NLP tasks simple and seamless. Each workflow was shaped by studying real products and diverse user needs, with a clear, intuitive interface that keeps the journey straightforward.
This is just the start. Spectrum will keep evolving through feedback, usability testing, and data — a commitment to continuous improvement, not an incomplete product.
In case you want to contact me for further projects, you can reach out to me at pradhyumnaag30@gmail.com.